
私は個人開発で、毎朝トレンドを調べて Telegram に流す定時バッチを運用している。Brave Search で記事を集め、LLM に日本語で要約・整形させて配信する、よくある構成だ。
ある朝、配信されたリサーチがこうなっていた。
・サブスクリプション から 使用量 係り に 方向 けた アウトカム 焦点 構造 への 変更。
・TikTok を 利用させた バリデーション、インディー・ハッカー 界隈 ニョり 未ニョり 低位 ある。
日本語が崩壊している。しかもバッチのログ上は「正常終了」。エラーは出ていない。本記事では、なぜこうなったか、そして「LLM が壊れたときの壊れ方」をどう設計し直したかを記録する。実は、200 で返ってくるのに期待通り動かない「失敗が見えない失敗」の怖さは 別記事(200 で返るのに動かないデバッグ記録) でも書いた。今回はその LLM 品質版だ。
📋 この記事でわかること
- 多段 LLM フォールバックで「最後に何が出るか」を設計しないと最弱モデルのゴミが本番に出る理由
- HTTP 200=正常という暗黙の前提が、崩壊出力のサイレント配信を生む仕組み
- 品質が落ちる経路に落ちるくらいなら「止めて通知する」フォールバック設計
- 無料枠が全滅したとき、サブスクリプションの
claude -pを定時バッチの LLM に据える方法 - launchd / cron 特有の認証・レート制限のハマりどころ
構成:3段フォールバックの統合ランナー
要約・整形には、複数の LLM を順に試す統合ランナー run_llm を使っていた。当時の優先順位は「Gemini → Codex → ローカル LLM」。コードの骨子はこうだ。
def run_llm(prompt: str, *, cwd: Path) -> str:
runner_errors = {}
# 1st: Gemini
if is_gemini_available():
try:
return run_gemini(prompt, cwd=cwd)
except RuntimeError as e:
runner_errors["Gemini"] = str(e)
# 2nd: Codex
try:
return run_codex(prompt, cwd=cwd)
except RuntimeError as e:
runner_errors["Codex"] = str(e)
# 3rd: ローカル LLM(最終フォールバック)
if is_local_available():
return run_local(prompt)
raise RuntimeError(f"全ランナー失敗: {runner_errors}")
一見、堅牢だ。3つも経路があるのだから、どれか1つは生きているだろう、と。問題は「3つ目に何が出てくるか」を真剣に考えていなかったことだった。
原因:上2段が同時に死んでいた
ログを追うと、上2段が両方失敗していた。
- Gemini:個人向けの無料枠が打ち切りになり、認証段階で
IneligibleTierErrorを返すようになっていた。一時障害ではなく恒久的な仕様変更だ。 - Codex:使用量の上限に達して当面使えない状態。加えて連携していた外部 MCP のトークンが失効し、ワーカーがクラッシュしていた。
つまりクラウド経路が2つとも、しかも別々の理由で、同時に死んでいた。残ったのは3段目のローカル LLM。これは量子化された軽量モデルで、英語のメモを日本語に整形させると、冒頭のようにトークン単位で崩壊することがあった。
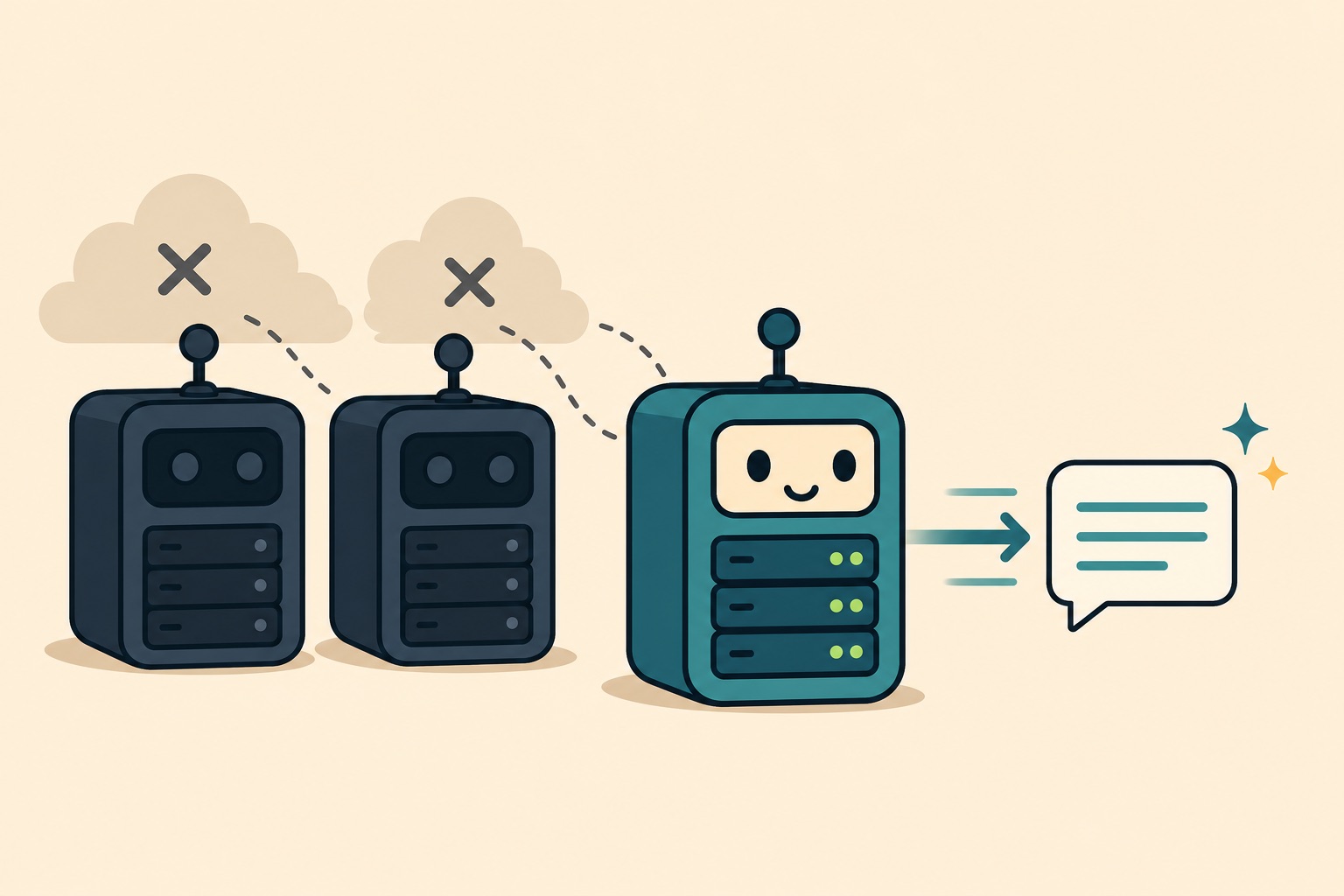
無料 LLM や利用枠つきのサービスは、ある日突然使えなくなる。フォールバックの最終段に「品質が保証できないモデル」を置いていると、上が全滅した日にそのゴミがそのまま本番に出る。
本当の問題は「成功扱い」だった
しかし、より怖かったのは別の点だ。崩壊した日本語でも、Telegram への送信は HTTP 200 で成功し、バッチは「正常終了」と記録していた。
response = run_llm(prompt, cwd=BASE_DIR) # 崩壊出力でも例外は出ない
if not send_message(response): # 送信は 200 で成功する
raise RuntimeError("送信失敗")
# → 何事もなく正常終了
例外が飛ばない以上、監視もアラートも反応しない。「動いている」ことと「正しく動いている」ことの区別を、コードがまったく持っていなかったわけだ。結果として、崩壊出力が毎朝サイレントに配信され続けていた。自分で気づくまで何日も。自動化で一番こわいのは、エラーで止まることではなく、壊れたまま成功し続けることだ。同じ轍は、個人 bot が自分の API に自己 DoS していた話 でも踏んでいる。
直し方1:崩壊するくらいなら止める
最初に入れたのは「品質を保証できない経路に落ちるくらいなら、配信せず止めて通知する」という安全策だ。run_llm に、ローカルフォールバックを抑止するフラグを足した。
def run_llm(prompt, *, cwd, allow_local_fallback: bool = True) -> str:
runner_errors = {}
# (Gemini → Codex を試す。両方失敗したら↓)
if not allow_local_fallback:
raise RuntimeError(
f"クラウドLLMが両方失敗、ローカルは抑止: {runner_errors}"
)
# 通常時のみローカルへ
...
日本語の整形が必須なレポート系ジョブは、すべて allow_local_fallback=False で呼ぶようにした。これでクラウドが全滅すると run_llm は例外を送出し、各ジョブの呼び出し側がそれを捕まえて「失敗通知」や、LLM を使わないテンプレ生成にフォールバックする。崩壊出力が配信される経路そのものを断ったわけだ。

ポイントは、フォールバックを「とにかく何か返す」ではなく「品質が落ちるなら、むしろ止めて知らせる」に倒したことだ。多段フォールバックは、各段の「成功」が同じ品質を意味しないなら、最弱の段に落ちた時点で失敗扱いにした方が安全な場合がある。
直し方2:主役のLLMを claude -p に寄せた
止めるだけでは配信されないので、品質の出る経路を立て直す必要がある。手元には Claude Code のサブスクリプションがあった。Claude Code は -p(print / ヘッドレス)モードで、プロンプトを渡すと応答だけを返してくれる。
echo "次のメモを自然な日本語で要約して" | claude -p --model sonnet --output-format text
これを呼ぶランナーを書いて、run_llm の優先順位の先頭に置いた。
def run_claude(prompt, *, cwd) -> str:
result = subprocess.run(
["claude", "-p", "--model", "sonnet", "--output-format", "text",
# 純粋なテキスト整形なのでツール類は使わせない
"--disallowedTools", "Bash,Edit,Write,Read,WebFetch,WebSearch"],
input=prompt, capture_output=True, text=True,
)
if result.returncode != 0:
raise RuntimeError(result.stderr[:400])
return result.stdout.strip()
要約・整形は軽い仕事なので、モデルは sonnet で十分だ。これで「無料枠の生き死に」に振り回されず、サブスクリプションの枠で安定して日本語整形が回るようになった。優先順位は Claude → Gemini → Codex → ローカル、という並びだ。
ハマりどころ:cron / launchd と認証
claude -p を手元のシェルで叩くと動くのに、env -i で環境変数を剥いだ最小環境で叩くと 401 Invalid authentication credentials で落ちる、という現象に出くわした。
最初は「スケジューラ(launchd)から起動しても認証が通らないのでは」と疑った。が、実際に launchd でジョブを叩いてみると、ちゃんと認証が通って成功する。からくりは、Claude Code のサブスクリプション認証がキーチェーンに保管されていて、launchd の LaunchAgent はユーザーの GUI セッション内で動くためキーチェーンにアクセスできる、という点だった。env -i はそのセッション文脈ごと落としてしまうので、再現環境としては厳しすぎたわけだ。
教訓は2つ。env -i はスケジューラの忠実な再現ではないこと。そして、最終的な動作確認は推測ではなく実際のスケジューラ経由で行うこと。ローカルの定時ジョブで認証や PATH 周りにハマるのは定番なので、ここは実機で確かめるしかない。
ハマりどころ:レート制限とスケジュール衝突
もう1つ。複数のレポートジョブを同時に走らせたところ、一番大きなプロンプトを投げるジョブだけが入力トークンのレート制限に当たって失敗した。調べると、同じ時刻に2つのジョブを発火させていたのが原因だった。片方は毎日、もう片方は週1で、たまたま同じ時刻に重なっていた。同時に LLM へ集中すると、分あたりの入力トークン上限を超える。
直し方は単純で、片方の発火時刻を10分ずらしただけだ。
<key>Minute</key>
- <integer>0</integer>
+ <integer>10</integer>
レート制限は「総量」だけでなく「単位時間あたり」で効く。重いジョブを同時刻に並べないというスケジュール設計も、立派なフォールバック対策の一部だった。
まとめ:壊れ方まで設計する
今回の学びを表に整理する。
| 観点 | やりがちな前提 | 設計し直したこと |
|---|---|---|
| 多段フォールバック | 経路が多ければ堅牢 | 最弱段に落ちるなら失敗扱いにして止める |
| 成功判定 | 例外なし・200=正常 | 「正しく成功」を別に検証し、劣化を可視化 |
| LLM 依存 | 無料枠は使い続けられる | 安定枠(サブスク)に主役を寄せる |
| スケジュール | 同時刻でも問題ない | 重いジョブを時間分散しレート制限を回避 |
「動かす」設計だけでなく「壊れたときどう壊れるか」まで設計して、ようやく自動化は安心して放っておける。崩壊日本語を毎朝配信していた私が言うのだから、間違いない。
よくある質問
Q. 多段フォールバックがあるのに、なぜ崩壊出力が出たのですか?
上位2経路(クラウドLLM)が別々の理由で同時に死に、品質を保証できない最終段のローカルモデルに落ちたためです。多段フォールバックは経路の数ではなく「最後に何が出るか」を設計して初めて意味を持ちます。最弱段に品質保証のないものを置くなら、そこへ落ちた時点で失敗扱いにする選択肢を持つべきです。
Q. なぜエラーにならず「正常終了」していたのですか?
崩壊した日本語でも Telegram への送信は HTTP 200 で成功し、コードはそれを正常とみなしていたからです。「動いている」ことと「正しく動いている」ことをコードが区別していなかったため、例外も飛ばず監視も反応せず、サイレントに配信され続けました。
Q. ローカルLLMを最終フォールバックに置くのは間違いですか?
用途次第です。品質が多少落ちても「何か返ること」に価値がある処理なら有効です。しかし日本語整形のように品質が崩れると配信物として成立しない処理では、最弱段に落ちるくらいなら止めて通知する方が安全です。フォールバックは『とにかく返す』だけが正解ではありません。
✅ まとめ
- 多段フォールバックは「最後に何が出るか」を決めて初めて完成する。最弱段に品質保証のないものを置くなら、そこへ落ちた時点で失敗扱いにする選択肢を持つ。
- 「成功」と「正しく成功」を分ける。HTTP 200 や例外なし=正常という暗黙の前提が、サイレントな崩壊配信を生む。
- 無料枠の依存は突然死ぬ前提で組む。安定枠に主役を寄せ、単一障害点と冗長性のトレードオフは意識的に選ぶ。
次のアクションとして、自分の定時ジョブが「LLM やコストの伴う処理に失敗したとき、何を返すか/何を配信するか」を1つ確認してみてほしい。崩壊しても配信してしまう経路が、たいてい1つは見つかる。

コメント